ユニコード(Unicode)とは?
ユニコードとは?をネットで検索すると、
「一般の文字コードが、特定の言語を表記するために作られたものであるのに対して、世界中のすべての言語を単一の文字コードで表現することを目的に作られている規格」みたいな説明がある。
なかなかピンとこない。また「マイクロソフトがUnicodeに対応したのは,「Windows 98」と「Windows NT 4.0」以降である。」との説明もある。またまたピンとこない。
文字コードとは何?/ユニコードじゃないといけないの?/おそらく細かな仕様で特に知らなく良いのでは?/と悶々と思ってしまう。
ひとまずユニコードは置いておいて、「コンピュータで文字をどのように表現しているか?」をまず理解した方が良さそうだ。
コンピュータの文字の表現
悶々と。
- 日本版Windowsでは、文字の入力では文字コードShift-JISが利用できる。–>良く分からないけど、プログラム作る時も、日本語を入力する時は、たしか出てきたな。細かく分からないけど。
- プログラム開発する時に、アスキーコード(ASCII)の表があって、なんか使ってたな。–>英語と特殊文字だけ定義されていて、Shift-JISとの関係が分からないな。
- UTF-8、UTF-16、Linuxでは、EUC-JPというものもあったな。いろいろあるけど、ユニコードとは関係ないじゃないかな?
コンピュータの歴史は、アメリカから始まったので、まずはアスキーコードを見てみよう。
アスキーコードとは
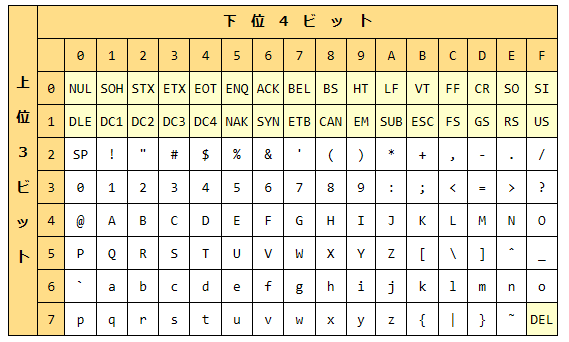
ASCIIとは、アルファベットや数字、記号などを収録した文字コードの一つ。最も基本的な文字コードとして世界的に普及している。良く見るアスキーコード表は、以下の通り。
これから、理解しよう。
コンピュータの内部表現
コンピュータは、人間が理解できるAの文字とか色などは、直接、理解できません。
コンピュータは、電気が流れている(On)、流れていない(Off)の2パターンしか理解できません。しかし、以下のようにOnの場合1、Offの場合0を8つならべれば、2の8乗のパターンの識別が可能です0
00000000
これは、10進数(通常、私たちが使用している)、60進法(時計)と同じ仲間で、2進数と呼ばれます。
同じ仲間とは、例えば、10進数では、9に1を足すと繰り上がり2桁の10になります。2進数では、0に1加えると1になり、更に1加えると桁が繰り上がり10になります。時計は59分に1を加えると1時間になります。
00000000 に1を加えると00000001になり、更に1を加えると00000010になります。
0または1の最小単位のことを1ビットと言います。8個あるので8bitです。
PCを購入する際、「Windows10は32bitと64bit版があるよ。」と聞いたことがあるかもしれません。あのbitです。
単位の話をすると、8bitは1バイトです。1024バイトは1K(キロ)バイト。1024K(キロ)バイトは1M(メガバイト)。1024Mバイトは1G(ギガバイト)。1024Gバイトは、1T(テラバイト)。1024Tは、1P(ペタバイト)。1024Pは、1E(エクサバイト)です。その後もゼタバイト、ヨタバイトと続きます。
1Gまでくると、スマホやPCを購入したことのある方は、聞いたことがあるでしょう。1Tはハードディスクの容量で聞いたことがある方もいると思います。
話を戻して、アスキーコードは、上位3ビット(最上のビットは0という決まりなので計、上位4ビット)、下位4bitで英語や数字、制御記号を表現しています。
上位4ビット 下位4ビット
0000 0000
例えば、Aは、コンピュータの内部で
0010 0001
と表現しています。
Mは、コンピュータの内部で
0010 1101
と表現しています。表で下位4ビットでDと書いてありますが、表は16進法で表現されています。10進数で13です。2進数では1101になります。16進法はF(10進法の15)に1加えると桁あがりして10となります。
なんで、またまた小難しい16進数が出てくるかというと、いろいろと表示とか便利なんですね。
例えば、Mは16進法では
4 D
と表示できるですね。ちなみにAは
4 1
になります。
実際、Aの文字とMの文字のコンピュータの内部表現の数値を見ることができます。さっそく見てみましょう。
まずは、Windowsに標準でインストールされているnotepadを開き、AMと入力して、test.txtと保存しましょう。
バイナリ表示できるソフトであれば何でも良いですが、ここでは無料で使用できる「Stirling」という高機能バイナリエディタをダウンロードして、test.txtを表示してみました。
(無料で使用できるソフトの開発者には、いつも感謝しております)
黄色い行は、見やすいように目盛りになっています。1バイト(8bit)単位に空白があります。
16進で表示しているので、41 4Dと確かに入っていますね。右側は実際の文字のAMが表示されています。
コンピュータの内部では、
英数字などの入力–>数値に置き換え
しています。表示する時は
数値–>英数字を表示
しています。

ちなみに色を指定する時、RGB(Red、Green、Blueの頭文字をとってRGBと表記)を指定します。Red、Green、Blueそれぞれで1バイトずつ使用して3バイトで表示します。
1バイトは1bitが8個ですので、2の8乗で256パターンの表現ができます。これが3バイトあるので16777216色表現することができます。通常フルカラーと呼ばれます。
RGBの指定で、青の10進数表現では、
0:0:255
16進表現では
#00 00 FF
となります。#は16進数を表しています。
カラーパレットで青を指定したり、文字でBuleと設定すると、コンピュータの内部では前述のように数値で情報を持っています。直接10進数でも、16進数でも入力できるソフトもあります。
以下は、Wordで文字の色を指定際に、青を選択しても良いし、ユーザー設定で10進数で入力も受け付けています。


アスキーコード表で、まだ悶々とするところがあります。NULやCRやLFなどの制御文字です。制御文字は、改行やタブなどを指します。
1例で改行のCRとLFを説明します。
- LF(Line Feed ラインフィード)
英語で、改行を意味する。カーソルを新しい行に移動すること。
- CR(Carriage Return キャリッジリターン)
英語で、復帰を意味する。カーソルを左端の位置に戻すこと。
- CR+LFそのまま。
CRとLFの融合。左端にカーソルを戻して改行すること。
WindowsやLinux、MACで改行コードが異なるというのを聞いたことがある方もいるのではないでしょうか?。実際、改行コードが異なります。以下のようになります。最近は自動で変換するソフトが増えましたが・・・
LF・・・UNIX/Linux
CR・・・MacOS
CR+LF・・・Microsoft Windows
改行コードは、WindowsではCR+LFですので、
2進数では
0000 1101 0000 1010
16進数では
0D 0A
となります。
notepadで文字AM入力後、改行したものをtest.txtと保存して、さっそくバイナリーエディタで見てみましょう。
思った通り、文字AMの後に0D 0Aが入っています。

Shift-JISとは?
英数字や制御文字が定義されたASCIIコードを内部表現に持つコンピュータは、とても使いやすくなった。しかし各国は、自分の言語を利用したいとのことで、各自で文字コードを検討しはじめた。これは1980年代のことである。いろいろな経過を踏みながら2000年頃にShift_JISが標準化された。
ではShift_JISとはどのようなものか?
1バイト(8bit)では2^8の256文字の表現が可能でアスキーコードが定義されていると、前に述べた。アスキーコードは1バイトを全部使用しようているわけでなく、空がある。
ここに目をつけて、空の部分に半角カタカナを定義した。それが、以下の表である。これで1バイトで、英数字と半角カタカナが利用できるようになり、利便性が増した。

しかし、広く普及するためには、ひらがな及び漢字も必要不可欠である。
日本語はかな、カナ、漢字も含めてると1万以上の文字がある。1バイトとでは足りないのは明らかで、2バイト(16bit)で、2^16で65536文字を数値に割り当てようという発想になる。通称、2バイト文字/マルチバイトである。
ここで、問題が1つ起きる。
(1)広く普及している1バイト文字のアスキーコードは、そのまま利用したい。
(2)かな漢字も利用したいので2バイトの文字にしなければならない。
どちらの条件も満たすように、
(1)1バイト文字(アスキー文字)は、そのまま使えばよい。
(2)かな漢字は、2バイト文字を使えばよい
(3)1バイト文字も2バイト文字も混ぜても良い
と定義した。例えば aあbいのように1バイト文字と2バイト文字を混ぜて使う方法である。そのままでは、コンピュータは理解できない。そこで、
1バイト文字の残りの空に目をつけて、
(1)1バイト目に使っていない0x80-0x9F に値が入っていたら(注)、2バイト目も参照して2バイト文字として扱う
(2)1バイト目に使っていない0x80-0x9F に値が入っていなかったら、1バイト文字として扱う
(注)2バイト文字は0x80-0x9F に値が入りようにしてある。
としました。(過去の資産のアスキーコードも継承しつつ、日本語文字コードにも対応した画期的なアイデアです)
日本では、ASCIIとSHIFT-JISを切り替えること無く、SHIFT-JISだけでASCIIの文字もそのまま表示できる環境ができました。
では、さっそく文字コードの中身を確認してみましょう。
Shift_Jisで「あ」「い」の文字コードは、以下のようになります。(Shift_Jisの文字コード表は、ネットで検索すると表示されますので確認したいかたはどうぞ)
「あ」
82 A0
「い」
82 A2
notepadで「AMあい」と入力して、保存します。保存時に文字コードが選択できますが、そのままANSIとして保存してください。Shift_JISで保存されます。

文字「A」「M」はそれぞれ、1バイト。「あ」、「い」はそれぞれ2バイトで、定義されている文字コードが表示されています。
このように日本では、特有のローカルルールのShift_JISを定義してコンピュータの普及に一役買いました。各国も独自のルーカルルールで自国内の文字コードを定義しました。
コンピュータが世界的に普及し、例えば日本で作成したソフトをいろいろな国で、その言語表記で販売するなど、文字コード処理が煩雑になり、国際的な規格が望まれました。
しれでは、世界中の文字を全て、重複しないように番号で管理しようということでユニコードが生まれました。
これは、とても便利で、世界中の文字コードの重複が無いわけですから、当然、Wordでも各国のこんにちはが、同じ文章の中にあっても良いわけです。

ユニコードについて
一般の文字コードが、特定の言語(例えば、日本語)を表記するために作られたものであるのに対して、世界中のすべての言語を単一の文字コードで表現することを目的に作られている規格です。世界中の文字に対して、番号が割り当てられ管理されています。
Unicodeで規定されている文字1つ1つには、最大で21bits(16進数で5~6桁)の数値が割り振られています。この数値をコードポイント(code point: 符号点、符号位置)という。
ここで割り振られている番号のことをコードポイントと言います。コードポイントは文字集合内の文字の位置です。コードポイントは16進数表示で頭にU+を付けて用いられます。
ちなみに、Unicodeでは、コードポイントの数値で文字を表すための表記として、「U+16進数」という表記を使います。「a」であればU+0061「あ」であればU+3042と表記する(以下、文字コードは全て16進数で表記する)。
一例として各文字のコードポイントは、以下のようになります。
| 文字 | コードポイント |
|---|---|
| a | U+0061 |
| b | U+0062 |
| あ | U+3042 |
| い | U+3044 |
さっそく、このコードポイント(文字コード)が正しいか?見てみよう。
Windowsのタスクバーの文字入力アイコン[A] or「あ]をマウス右クリックして、IMEパッドを選択すると、UNICODEの文字コード一覧が参照できます。ちなみにIMEとは、”input method editor”の略称で文字入力をサポートするソフトウエアのことである。
UNICODEの文字コード一覧を見てみると、なるほど世界の文字が入っている。各国が協力してよくぞ作ったと感心してしまいます。

UNICODEとUTF-8の関係は?
実は、このユニコードの21bitsのコードポイントは、そのままテキストファイルに保存されるわけではありません。なぜって?1文字で21bitも必ず使用すると、限りあるメモリ使用やディスク容量がもったいないからです。
アスキーコードで文字「A」は、1バイトあれば足ります。例えば、アスキーコードであれば「ABC123」は6バイトです。ユニコードでは6文字 × 21bitなので16バイト弱使用します。
ここでUTF-8が登場します。
UTF-8とは?
もっともポピュラーなアスキーコードは、従来のままで良いのは?。という発想から生まれた符号化文字コードです。符号化とは、オリジナルのデータを、一定のルールで別のデータ形式に変換することです。
UTF-8は、アスキー文字は1バイト、その他は2~4byteの可変長として表現します。ですので、UNICODE–>UTF-8 –>UNICODE のように一旦、UTF-8の形式にして、UNICODEへ復元できます。
現在はホームページやファイルの保存形式などで最も人気があります。なんといってもアスキーコード互換なので、過去の資産も継続して利用できます。
では、さっそくUTF-8の文字コードを見てみましょう。Nodepadを起動して、「abあい」と入力して、UTF-8形式でtest.txtと保存して、バイナリエディタで見てみましょう。
| 文字 | Unicodeコードポイント | UTF-8の文字コード |
|---|---|---|
| a | U+0061 | 61 (1バイト) |
| b | U+0062 | 62 (1バイト) |
| あ | U+3042 | E38182 |
| い | U+3044 | E38184 |
先頭に3バイトに何か情報が入っていて、以降のバイト列には、UTF-8の文字コードが入っているのが分かります。先頭の3バイトは、BOMです。BOMはバイトオーダーマーク(byte order mark)の略で、Unicodeで符号化したテキストの先頭に付与される数バイトのデータのことです。
プログラムがテキストデータを読み込む際に先頭の数バイトによりUnicodeのデータであることやどの種類の符号化形式を採用しているのかを判別しています。BOM付きのUTF-8であれば先頭の3バイトがBOMであり、<0xEF 0xBB 0xBF>というデータになります。BOM無しの場合は、先頭の3バイトがありません。
WindowsのNodepad(メモ帳)のファイル保存時に、UTF-8を選択すると、BOM付きのファイルとして保存されます。その他の高機能エディタのsakura editorなどでは、BOM付き、BOMなしを選択することができます。
本来、なくても構わないもので、Unicodeの規格では、「UTF-8においてBOMは容認されるが、必須でも勧められるものでもない」(Wikipedia)。
BOMがないとUTF-8だと認識できず、種々の問題が起こるものとして
Microsoft Office Excel (CSVファイル関連)がある。
通常はBOM無しで保存し、ソフトの入力時に問題あればでBOM有で保存するのが良いでしょう。

まとめ
UNICODEは、前述の説明通り冗長なため、UTF-8の符号化形式がありますが、その他に以下の符号化形式があります。
| No | 符号化形式 | 内容 |
| 1 | UTF-8 | 1~4Bytesの可変長で記録する |
| 2 | UTF-16 | 2Bytes以下に収まるコードポイントはそのまま2Bytesの整数として記録し、それを超えるものはペア(2×2で4Bytes)を使って記録する |
| 3 | UTF-32 | コードポイントをそのまま4Bytesの固定長で記録する |
BOMとエンディアン
コンピュータ内でバイトを並べるには、以下の2つの形式があります。エンディアンは、CPUで決まっています。
(1)リトル・エンディアン
下位8ビットを先に、上位8ビットを後に記述するものです。インテルのCPUがこの方式をとっています。
(2)ビッグ・エンディアンといい、
下位8ビットを後に、上位8ビットを先に記述するものです。モトローラやSunのCPUがこの方式をとっています。
UTF-8はバイト指向なので、エンディアンに関する問題はありません。エンディアンに関係なく、最初のバイトは常に最初のバイト、2番目のバイトは常に2番目のバイトです。
UTF-16,UTF-32は、バイトの並びに関係しているため、BOMをテキストの先頭に置き、プログラム側で判断するようにことになりました。プログラムはテキストの先頭を読み取り、FF, FE の順番であればリトル・エンディアン、逆であればビッグ・エンディアンと解釈して処理をするようにしました。
| エンコード方式 | BOM | |
|---|---|---|
| UTF-8 | EF BB BF |
|
| UTF-16 | ビッグエンディアン | FE FF |
| リトルエンディアン | FF FE |
|
| UTF-32 | ビッグエンディアン | 00 00 FE FF |
| リトルエンディアン | FF FE 00 00 |
|
まとめ
Unicodeは文字集合であり、メモリ/ディスクの観点からUTF-8やUTF-16やUTF-32の符号化方式が使用されています。
補足
メモ帳の保存形式
メモ帳で、ファイルを保存する際に、ANSI,Unicode,Unicode bug endian UTF-8が選択できます。以下の形式で保存されます。
 (1)ANSI
(1)ANSI
SJIS形式で保存します。日本語が含まれていない場合にはアスキーコードと互換性があります。
(2)Unicode
UTF-16のリトルエンディアン形式で保存します。
(3)Unicode big endian
UTF-16のビックエンディアン形式で保存します。
(4)UTF-8
UTF-8形式で保存します。アスキーコードと互換性があります。
参考)sakura editorの保存形式
保存時に、「Unicode」を選択した場合、メモ帳と同じで、UTF-16のリトルエンディアン形式で保存します。「UnicodeBE」を選択した場合には、UTF-16のビックエンディアン形式で保存します。
他のEditorでは、「Unicode」という情報だけでなく、符号化形式を選べるエディタもあります。分からなくなったらファイルを保存して16進表示して、自分で調べてみましょう。
VisualStudio2019のソースの保存形式
VisualStuido2019でC++コンソールアプリのプロジェクトを作成し、ソースを保存して確認したところ、デフォルト時のソースの保存は、Shift-JISです。
ユニコード対応アプリのプロジェクトを作成する際は、[構成プロパティ]->[詳細]->[文字コード] の「Unicode文字セットを使用する]を選択します。Windows が採用している Unicode の文字符号化方式は,UTF-16 です。